Let’s break down the concept of Transformers in a way that’s easy to grasp. Imagine you’re at a party where you’re trying to listen to a friend’s story, but you also want to pay attention to everything else going on around you. This is sort of what the Transformer technology does with words in a sentence—it listens to one word while also paying attention to the others around it to better understand the full context.
Introduction to Transformer
Transformers were introduced in the paper “Attention is All You Need” by Vaswani et al. in 2017. The key innovation of the transformer architecture is the self-attention mechanism, which allows models to weigh the importance of different parts of the input data differently. This is particularly useful in tasks involving natural language, where the relevance of words or phrases can be highly context-dependent.
Structure or High-Level Overview of Transformer
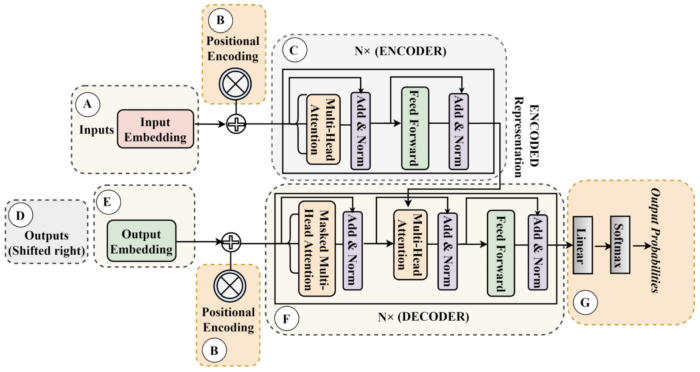
A transformer model consists of two main parts: the encoder and the decoder. Both parts are made up of layers that contain smaller units called attention heads.
-
- Encoder: It processes the input data in parallel and maps it into a higher-dimensional space, where the relationships between the data points (e.g., the words in a sentence) are captured. Each encoder layer performs self-attention and then passes its output through a feed-forward neural network.
-
- Input Embedding: Converts input tokens into vectors.
-
- Positional Encoding: Adds information about the position of each token in the sequence.
-
- N Encoder Layers: Each layer has two sub-layers:
-
- Multi-head Self-Attention: Allows the model to focus on different positions of the input sequence.
-
- Position-wise Feed-Forward Networks: Applies a linear transformation to each position separately and identically.
-
- N Encoder Layers: Each layer has two sub-layers:
-
- Encoder: It processes the input data in parallel and maps it into a higher-dimensional space, where the relationships between the data points (e.g., the words in a sentence) are captured. Each encoder layer performs self-attention and then passes its output through a feed-forward neural network.
-
- Decoder: It generates the output sequence, one element at a time, by considering the encoded input and what has been generated so far. Similar to the encoder, the decoder also performs self-attention but with a twist to prevent it from seeing future elements of the sequence it’s generating. This is known as masked self-attention.
-
- Output Embedding: Converts target tokens into vectors.
-
- Positional Encoding: Similar to the encoder, adds positional information.
-
- N Decoder Layers: Each layer has three sub-layers:
-
- Masked Multi-head Self-Attention: Prevents positions from attending to future positions during training.
-
- Multi-head Attention over Encoder’s Output: Allows each position in the decoder to attend over all positions in the encoder.
-
- Position-wise Feed-Forward Networks: Similar to the encoder’s feed-forward networks.
-
- N Decoder Layers: Each layer has three sub-layers:
-
- Decoder: It generates the output sequence, one element at a time, by considering the encoded input and what has been generated so far. Similar to the encoder, the decoder also performs self-attention but with a twist to prevent it from seeing future elements of the sequence it’s generating. This is known as masked self-attention.
Inputs
The input to a transformer model is typically a sequence of tokens. Tokens can be words, parts of words, or even characters, depending on the granularity of the model. Before being fed into the model, these tokens are converted into numerical vectors using embeddings. Additionally, positional encodings are added to these embeddings to give the model information about the position of each token in the sequence since the transformer itself does not inherently process tokens in order.
Outputs
The output of the transformer depends on the task it’s designed for. For instance, in a translation task, the output would be a sequence of tokens in the target language. In a sentiment analysis task, the output might be a single token or value representing the sentiment of the input text.
Self-Attention Mechanism
At the heart of the transformer architecture is the self-attention mechanism. This mechanism allows each token in the input sequence to be influenced by all other tokens. Self-attention computes three vectors for each token: a query vector (Q), a key vector (K), and a value vector (V). The self-attention score is calculated by taking the dot product of the query vector of a token with the key vector of all other tokens, followed by a softmax operation to obtain weights that sum to 1. These weights determine how much each token should attend to every other token in the sequence. The output of the self-attention layer is a weighted sum of these scores and the corresponding value vectors.
Multi-Head Attention
Transformers use multiple sets of attention mechanisms, called heads, to allow the model to jointly attend to information from different representation subspaces at different positions. This multi-head attention mechanism helps the transformer capture a richer understanding of the input sequence.
The Magic of Attention
The essence of the transformer model is the attention mechanism, which allows the model to focus on different parts of the input sequence when performing a task. The self-attention mechanism computes scores that determine how much focus to put on other parts of the input sequence when encoding or decoding a particular element. This mechanism enables the model to capture complex relationships and dependencies in the data, such as the context surrounding a particular word in a sentence.
Why Transformers Are Important
Transformers have significantly advanced the field of NLP for several reasons:
-
- Parallel Processing: Unlike previous architectures like recurrent neural networks (RNNs), transformers process all elements of the input data in parallel, leading to significant improvements in training speed.
-
- Scalability: Transformers are highly scalable, capable of handling very large models and datasets. This has enabled the development of models like GPT (Generative Pretrained Transformer) and BERT (Bidirectional Encoder Representations from Transformers), which have set new benchmarks in NLP.
-
- Versatility: Transformers have been successfully applied to a wide range of NLP tasks, including translation, summarization, question-answering, and more. Their ability to capture deep contextual relationships makes them highly effective across different languages and domains.
Conclusion
Transformers represent a major leap forward in the ability of machines to understand and generate natural language. By leveraging the power of self-attention, transformers can process complex language data in a way that is both efficient and effective. As the field of AI continues to evolve, transformers are likely to remain at the forefront, driving further advances in natural language processing and beyond.
References
-
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
-
- Raiaan, M. A. K., Mukta, M. S. H., Fatema, K., Fahad, N. M., Sakib, S., Mim, M. M. J., … & Azam, S. (2024). A review on large Language Models: Architectures, applications, taxonomies, open issues and challenges. IEEE Access.
You can also read posts on generative AI and large language model here:
-
- Large Language Models: A Compact Overview: https://ai-researchstudies.com/large-language-models-a-compact-overview/
-
- Generative AI: https://ai-researchstudies.com/generative-ai/
You also can download the presentation on the tranformer architecture from here: AI_Researcher_TransformerArchitectureLLM_Manisha
Thank you and happy reading! 🙂
It’s actually a nice and helpful piece of information. I’m glad
that you shared this helpful info with us.
Please keep us up to date like this. Thanks for
sharing.