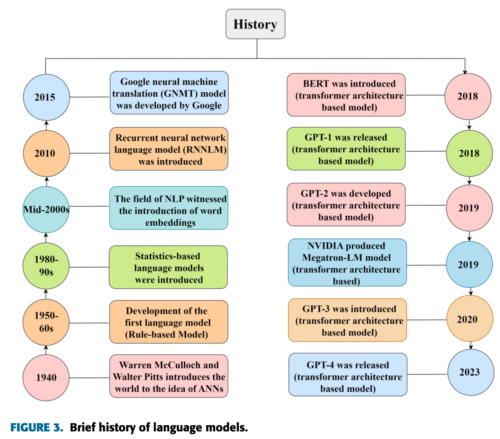
In this post, we are going to see the historical overview of the development of Language Models, from 1940 to 2023.
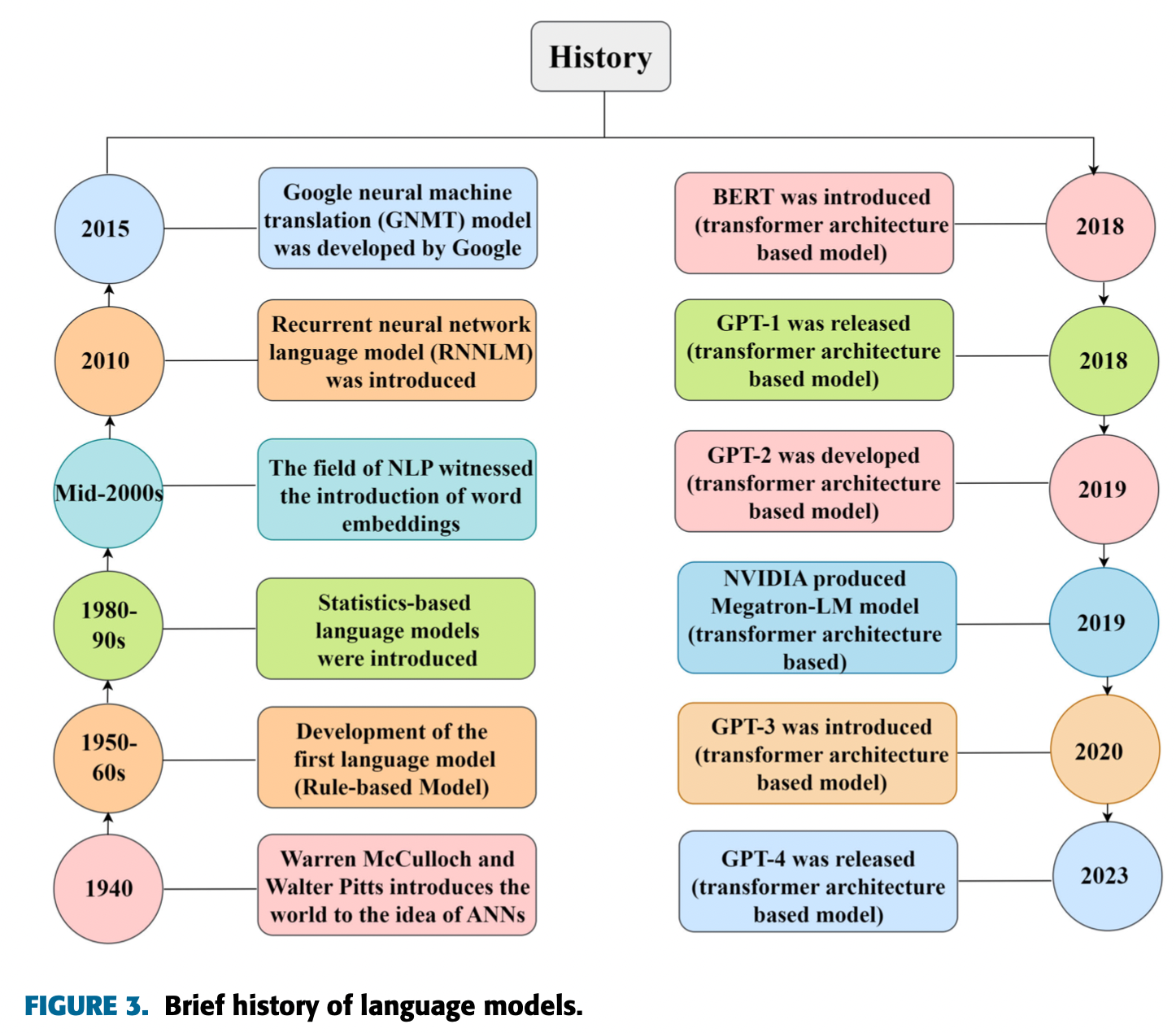
The figure 1 highlights the evolution from rule-based models, to statistical models, then onto the 2000s with the advancement of word embeddings in NLP. Key developments from 2010 onwards include recurrent neural network language models (RNNLM), Google’s Neural Machine Translation (GNMT), and the transformer architecture-based models like BERT, GPT and many more.. This progression shows the rapid advancement in language models. This figure from this paper. Now let’s see these developments step-by step.
Let’s recall to the 1940s.
In 1943, American neurophysiologist Warren McCulloch and cognitive psychologist Walter Pitts published a research study. The name of study is ‘A Logical Calculus of the ideas Imminent in Nervous Activity’. In this study, the first mathematical model of a Artificial Neural Networks was discussed. The paper provided a way to describe brain functions in abstract terms, and it showed that simple elements connected in a neural network can have immense computational power. I would say this is visionary work we see in the field of artificial intelligence.
Here goes the study reference:
McCulloch, W.S., Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics 5, 115–133 (1943). https://doi.org/10.1007/BF02478259
Progressing to the 1950s and 60s
We saw the development of the first language models. These were rule-based systems that operated on fixed algorithms.In this era, Researchers began to develop rule-based approaches to natural language processing. These methods relied on rules that were designed to analyze and understand the structure of language. So, one of the earliest examples of a rule-based system was the Georgetown-IBM experiment, which was conducted in 1954. The Georgetown-IBM experiment involved a machine that was programmed to translate sentences from Russian to English.
There was another significant advancement we see in 1966 by Joseph Weizenbaum that is the “ELIZA”. It is a computer program which makes natural language conversation with a machine. ELIZA was a rule-based chatbot that was designed to simulate a conversation with a therapist, and it is considered to be one of the earliest examples of a natural language model.
Here I left the reference study:
Weizenbaum, J. (1966). ELIZA—a computer program for the study of natural language communication between man and machine. Communications of the ACM, 9(1), 36-45.
Moving on 1980s and 90s developments
In this decade,researchers continued to develop new approaches to natural language processing such as statistics-based models. The NLP used probabilistic models to analyze language. One of the pioneers of this approach was Karen Sparck Jones, who introduced the concept of inverse document frequency, which is now a key component of modern search engines.
You can check the paper on inverse document frequency (IDF):
Sparck Jones, K. (1972). A statistical interpretation of term specificity and its application in retrieval. Journal of documentation, 28(1), 11-21.
So In the 1990s
The field saw machine learning approaches for natural language processing. Meaning ML algorithms were used to learn from large amounts of language data. One of the earliest examples of this approach was the Hidden Markov Model, which was used to recognize speech.
You can check one interesting paper on this:
Rabiner, L. R. (1989). A tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE, 77(2), 257-286.
In the early 2000s, researchers began to use deep learning techniques, which are now a key component of modern natural language models.
In the mid-2000s, Natural Language Processing saw a change with the introduction of word embeddings. The embedding is used in text analysis. Basically, the representation is a real-valued vector that encodes the meaning of the word in such a way that the words that are closer in the vector space are expected to be similar in meaning.
You can check one interesting paper on this:
James, H. M. (2000). Speech and language processing: An introduction to natural language processing computational linguistics and speech recognition. Person Education, Inc.
After 2010
We enter into Recurrent Neural Network Language Models (RNNLMs). These LLMs were capable of remembering previous information, and it a significant leap towards understanding context. RNNLM is a type of neural net language models which contains the RNNs in the network. As we know that RNN is suitable for modeling the sequential data in natural language.
You can the paper on Extensions of recurrent neural network language model:
Mikolov, T., Kombrink, S., Burget, L., Černocký, J., & Khudanpur, S. (2011, May). Extensions of recurrent neural network language model. In 2011 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5528-5531). IEEE.
We can say year 2015 was a remarkable year for Google as they developed the Google’s Neural Machine Translation model in this year. Google Neural Machine Translation (GNMT) is a neural machine translation (NMT) system introduced in November 2016 that uses an artificial neural network to increase accuracy in language Translate. This model was a substantial improvement in translation quality of language more accurately than ever before.
A Paper on the GNMT:
Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., … & Dean, J. (2016). Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144.
The game-changer arrived in 2017
With the Transformer model architecture, which used ‘attention mechanisms’. In 2018, two models were released: Generative Pre-trained Transformer 1 (GPT-1) by OpenAI and Bidirectional Encoder Representations from Transformers(BERT) by Google. Both used the Transformer architecture, but with different approaches. GPT for generative tasks, BERT for understanding context. BERT is a language model. It was introduced by google researchers.
From 2018, it was a quick progression.
GPT-2 was released in 2019 which was a refined version of GPT-1. GPT-2 was pre-trained a dataset of 8 million web pages. NVIDIA wasn’t far behind. In 2019, they produced Megatron-LM, a transformer-based LLMs. Then Generative Pre-trained Transformer 3 (GPT-3) is a large language model released by OpenAI in 2020. Like GPT-2, it is a decoder-only transformer model of deep neural network. Then, the GPT-4 is fourth series of GPT. It is a multimodal large language model. It was launched in 2023.
Possible future development
With such fast progress in generative AI since 2018, we can possibly have 1 bit based LLM model very soon and these models could enable deployment on low-power devices such as smart phone in less expenses.
I have created a presentation on the history of lanaguge model, you can download it from here: AI_Researcher_historyLanguageModel_compressed
There is a post on generative AI, you can check it here: 2. Generative AI
Happy reading!
Thank you and see you in the next!:)