In this post, we are going to explore a significant shift in artificial intelligence, from traditional large language models to 1-bit LLMs.
The growing number of LLMs is an extraordinary development in the field of AI. In recent years, several research studies have been conducted on language modelling. Researchers from various fields have contributed on the LLMs developments.
Here are some points that we are going to see in a bit:
- What traditional LLMs are?
- Introduction of the innovative concept of 1-bit LLMs.
- Closer look at the BitNet b1.58 model.
- BitNet b1.58 model’s performance and discuss what this all means for the future of technology.
Understanding Traditional LLM
First, let’s understand the basics about the traditional LLMs.
Large language models (LLMs) have achieved remarkable performance in most NLP tasks.Language models like GPT (Generative Pre-trained Transformer) traditionally use 16-bit floating points to operate. While this precision is great for making complex calculations, it makes models large in size and high in cost. Aditionally, these models are slow due to high latency, they consume a lot of memory and high energy and due to these factors, the advanced language models can not be easily implemented on devices like smartphones, edge devices that have insufficient computing power and storage.
So, what are the possible options to reduce the size of LLMs? There are two feasible options:
- Reducing model parameters
- Reducing the model parameter precision
However, reducing these parameter can make the LLMs less powerful as the LLMs are trained on less number of parameters.
What is 1-bit LLM?
To over the challenges with traditional LLMs like taking too long to respond, needing lots of memory and energy, there is an interesting recent research study happened on LLM which is 1-bit LLMs. Now, let’s see what is the 1-bit LLM. Imagine, reducing all those complex calculations to something as simple as binary bits and that is the core idea behind 1-bit LLMs, where each parameter is just +1 or -1, in a way it is simplifying the computing process. For example, it is just like turning a complex/abstract color painting into a simple black and white sketch.
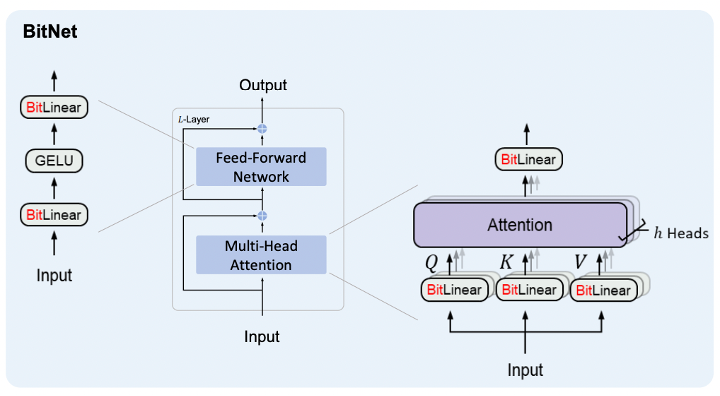
Here, the Fig 1 shows BitNet architecture, which is a specific design of a 1-bit Transformer. This BitNet has two parts, attention mechanisms and feed-forward networks, which are standard components of many AI language models. Actually, these components help the model to focus on important parts of the input data and process it to get the output. In BitNet, the operations that usually involve complex math are done with ‘BitLinear’ operations, so again it is using only 1-bit representations.
Therefore, this simplification helps the model run faster and use less power and memory. It makes deployment of the LLMs more cost-effective and easier in different environments.
With that, we will see on a fascinating development in AI called Bitnet b1.58 LLM, this research is done by Microsoft research in collaboration with Univ. of Chinese Academy of Sciences. Bitnet b1.58 LLM is a variant of a language model or LLM that is based on a framework called Bitnet. Normally, language models use a wide range of numbers to make decisions. But, the Bitnet b1.58 simplifies this by using just three numbers: -1, 0, and +1. This is like using a simple ‘yes’, ‘no’, or ‘maybe’ to make decisions instead of a long list of possibilities. So let’s see what is 1.58 bit LLM.
What is the 1.58-bit concept?
In Bitnet b1.58, instead of using just two states (-1 and +1), an extra state that is (0) is introduced in the architecture. But you can not just call it a 3-bit model because that would imply 8 different states (from 000 to 111 in binary). So, we have to find a way to express that we’re using a system that’s more complex than 1-bit but not as complex as a full 3-bit system. By doing some math specifically, taking the log base 2 of 3—we get approximately 1.58 value. This reflects the increase in complexity from a simple on-off (0-1) state to a system with three possible states that ternary system (-1, 0, +1).
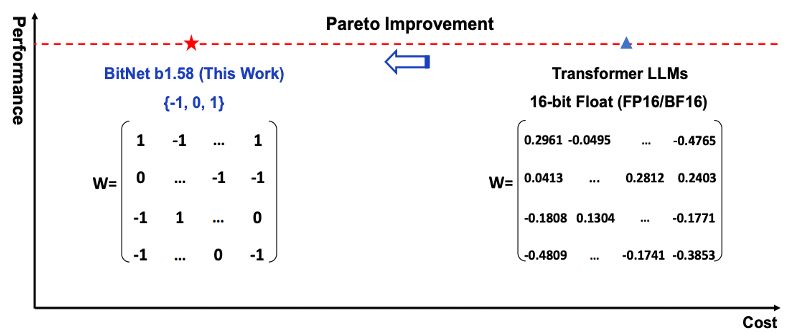
Now, take a look at the Fig. 2 here. It shows a balance between performance and cost. The red line with the red star—that is Bitnet b1.58. It performs quite well while keeping costs down (that we will see in a bit). On the right side, traditional 16-bit precision models, such as the transformers we often talk about, are shown to be more costly..
The Fig.3 shows a transitioning from high to low bit precision:

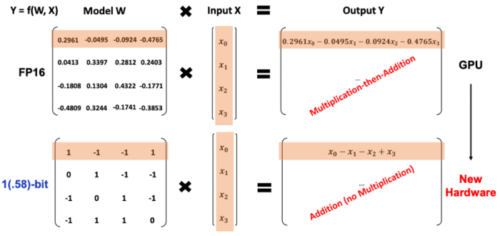
Lets see the mathematical formulation:
- A traditional model (shown at the top of the equation section) multiplies more complex, precise numbers (like 0.2961) with the input to get a result. This is a floating-point operation which is standard but resource intensive as it include multiplication and addition operations.
- Whereas, BitNet b1.58 (shown at the bottom of the equation section) uses its ternary system to perform simpler addition operations which avoids complex multiplication altogether. Here, it converts, the model weights into either +1 or 0 or -1 and generate a weight matrix. Due to this, simplification of the model is no longer dealing with a wide range of decimal numbers, but rather a simple set of three possible integers.
- With only three possible values for weights, the process of getting the output changes. Instead of performing multiplications that require high precision, the model can only use addition and subtraction.
- For example,
- If the weight is -1 and the input is x₁, the operation is simply -x₁ which means (just a subtraction).
- If the weight is 1, the operation is x₁ which means (just an addition operation).
- If the weight is 0, the input value is ignored, as multiplying by zero gives zero.
- Addition and subtraction are much simpler and faster for computers to execute than multiplication, especially when dealing with large matrices. It means that less memory is required to store the model and that the energy needed for computations is greatly reduced.
- The move from floating-point to integer operations allows for the use of hardware that is designed for simple, quick, and low-power integer arithmetic.
Thus, there are three key advantages:
- Reduced latency: The time it takes for the AI to make a decision is shorter because the calculations are simpler.
- Memory use: Less memory is needed to store and process the simpler weight system.
- Energy consumption: With fewer and simpler calculations, the amount of energy used is greatly reduced.
Result
Now, we will see the results of the study. Here we will two types of models are being compared: the BitNet b1.58 model and traditional 16-bit precision LLaMA LLM.
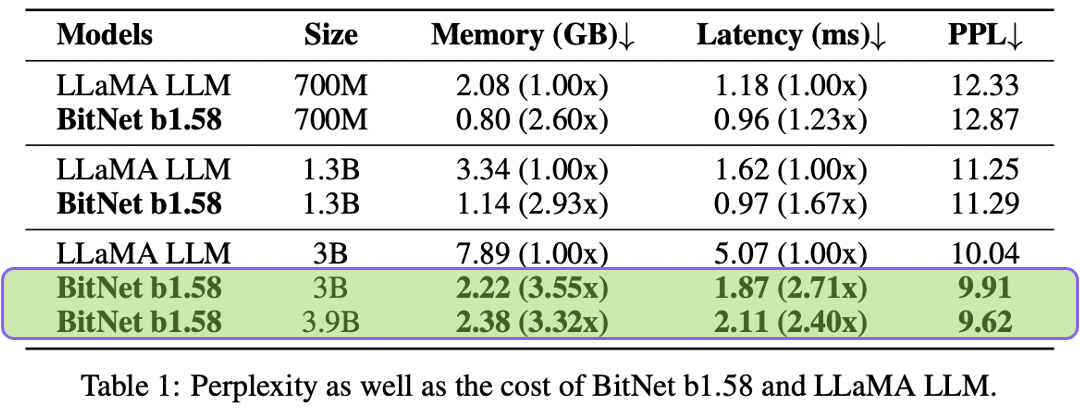
In the Table 1, we see the model name, size of parameters used in the model, memory (it means how much memory each model uses), latency (it measures how long it takes for the model to respond once it is been given an input. Lower latency is better because it means the model can process information faster), and PPL (perplexity: It is a measure of how well a language model predicts a new data). Lower perplexity means better performance, which means the model is more ‘certain’ about the language.
Here we can see,
- Across all model sizes, BitNet b1.58 requires significantly less memory than the LLaMA LLM. It maintains better latency and similar perplexity as compare to LLAMA LLMs. This means that the BitNet b1.58 model is more efficient without sacrificing the quality of language processing.
- In the highlighted rows, the 3B size show that even as models scale up, the BitNet b1.58 maintains its efficiency gains. The 3.9B size of BitNet b1.58, in particular, shows a great balance between size and efficiency.

Now, Let’s see the performance comparison in Table 2, focusing on zero-shot accuracy between the LLaMA LLM and BitNet b1.58 across various sizes. Zero-shot accuracy refers to ability of the model to correctly perform tasks it has not specifically been trained on. Let’s break down the information:
In the table, ARCe (ARC-Easy), ARCc (ARC-Challenge ), HS, BQ (BoolQ), OQ (Open- bookQA), PQ, and WGe (Winogrande), there are task Performance Metrics. These abbreviations are used for different types of natural language processing (NLP) tasks. And Each column shows the accuracy percentage for each model on that specific task.
Analysis of data,
- The highlighted rows for the 3B and 3.9B sizes show BitNet b1.58 outperforming the LLaMA LLM on many task tasks, for example: ARC-Challenge and Winogrande and the overall accuracy of the BitNet is higher than LLaMa model..
- This indicates, as the models get larger, the average zero-shot accuracy tends to increase for both types of models.
Now the question of how BitNet b1.58 reduces inference costs and improves throughput.
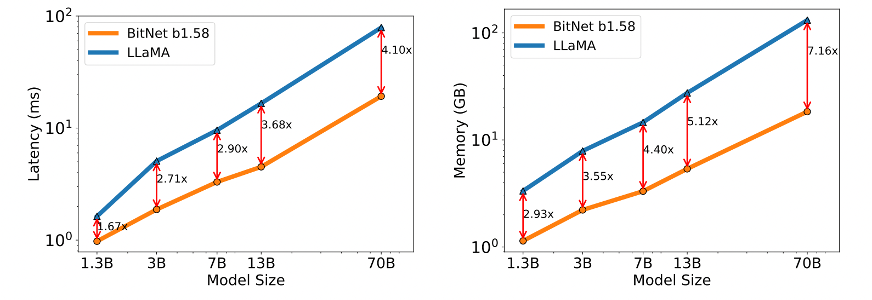
So, there are two graphs in Fig. 4, one depicting decoding latency and the other memory consumption, and the both are functions of model size. Let me explain what is Inference cost and throughput. Inference cost refers to the computational expense of the model when it is making predictions, and throughput refers to how much data the model can process in a given amount of time.
- Decoding Latency (on Left Graph) shows that as the model size increases, the latency, or time taken for the model to respond, increases for both models. However, the latency for BitNet b1.58 is consistently lower across all model sizes compared to LLaMA. The numbers (1.67x, 2.71x, etc.) indicate how much faster BitNet b1.58 is in terms of latency compared to LLaMA at each model size.
- Similarly, the graph on Memory Consumption (on Right side) shows memory consumption that BitNet b1.58 uses significantly less memory than LLaMA at equivalent model sizes. The numbers shown (2.93x, 3.55x, etc.) represent the factor by which BitNet b1.58 reduces memory usage relative to LLaMA model.
Another things is the Table 3 here, it provides a direct comparison between the BitNet b1.58 and LLaMA models, both with 70 billion parameters.

- Third column, Max Batch Size indicates the maximum number of inputs the model can process at once. BitNet b1.58 can handle a much larger batch size (that is 176) compared to LLaMA (that is 16), that means BitNet is capable of handling more data at once by 11x times than LLaMa model.
- Forth column indicates Throughput: it is measured in tokens per second—it is a basic units of text the model processes. We can see that the BitNet b1.58 achieves a throughput nearly nine times greater than LLaMA, showing it can process more language data per second.
Now let’s see, how the BitNet b1.58 do energy savings and computational efficiency on modern hardware?
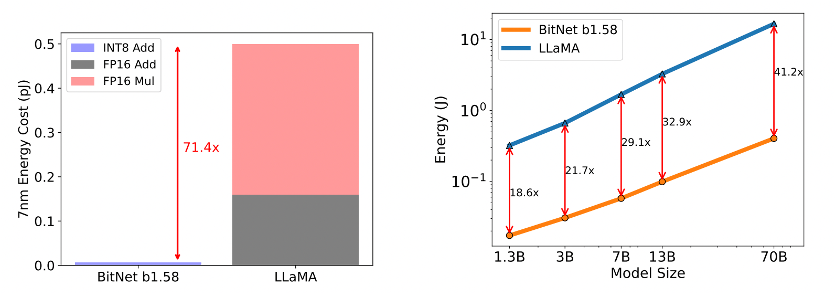
The Fig. 5 show, the left-hand bar chart compares the arithmetic operations’ energy cost of BitNet b1.58 with LLaMA. It breaks down the energy consumption into three components:
- INT8 Add: The energy used by BitNet b1.58 for integer addition operations, which is very low.
- FP16 Add: The energy used by LLaMA for 16-bit floating-point addition operations.
- FP16 Mul: The energy used by LLaMA for 16-bit floating-point multiplication operations.
- And the red line indicates that BitNet b1.58 has a significant 71.4x reduction in the energy cost for arithmetic operations compared to LLaMA model.
- Now lets see the graph on the right-hand side, it plots the end-to-end energy cost for various model sizes, from 1.3B to 70B parameters. The y-axis is on a logarithmic scale, indicating the differences in energy consumption. The graph shows that BitNet b1.58 consumes much less energy than LLaMA across all model sizes, with the differences increasing as the models get larger. The numbers (18.6x, 21.7x, etc.) show that BitNet b1.58 is more energy-efficient compared to LLaMA.

Lets check the the Table 4, it shows the performance of BitNet b1.58 and StableLM-3B on different standard language understanding benchmarks, measured in terms of accuracy on tasks such as, Winogrande (Winogrande), PIQA (Physical Interaction QA), SciQ, LAMBADA, ARC-easy and the Avg. (the column shows the average performance across these tasks). In summary, avg. accuracy, 74.34 indicates that BitNet b1.58 performs competitively, with slightly higher average scores than StableLM-3B.
Conclusion
the paper indicates that the 1.58-bit LLM has introduced a new rule for how AI models can grow and improve in resources like memory and processing power. Along with that, this approach is significant because it promises to deliver high-performance AI models that are also cost-effective. High performance means that the models are very good at understanding and generating human language, and cost-effective means that they can give high performance with less expense in terms of computational resources and energy. Finally, this research set the way for innovations in both the hardware that runs these models.
That is all for this post.
Thank you and Happy reading!