In this post we are going to explore, prompting vs fine-tuning, key difference between prompting and fine-tuning, how prompting and fine-tuning work?, and three prompting techniques.
So, let’s get started!
Prompting Vs Fine-Tuning
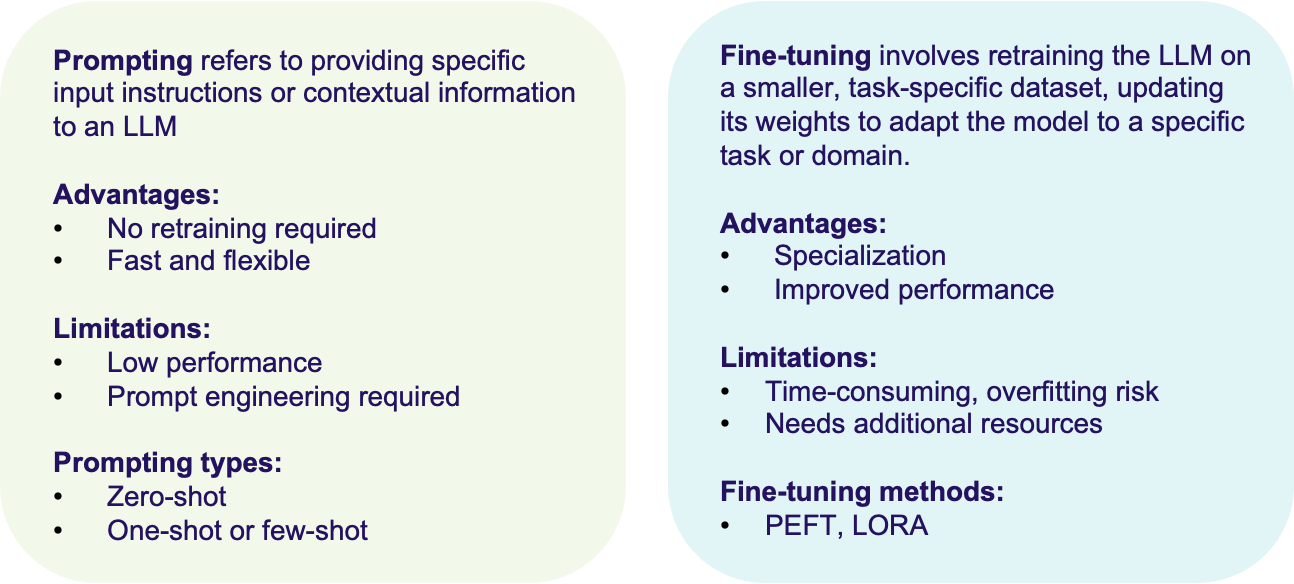
What is prompting? (Refer Figure 1):
- Definition: Prompting means providing specific input instructions or contextual information to an LLM to guide its output without changing the model’s basic parameters.
- How it works: Users provide a prompt (typically a piece of text or a question) to instruct the model to generate a desired response. For instance, if the model is asked: “Translate ‘orange’ word to Spanish”, the model will use its pre-trained knowledge to generate “naranja” without any adjusting to its weights/structure.
- Types of Prompting:
- Zero-shot prompting: The model is asked to perform a task without any examples. Example: “Translate ‘orange’ word into French language”.
- One-shot or few-shot prompting: The model is inputed with one or a few examples before performing the task. Example: “Translate ‘orange’ = ‘naranja’, ‘apple’ = ?”.
- Advantages:
- No retraining required: It means the model can adapt to a wide range of tasks without adjusting its parameters.
- Fast and flexible: Users can create prompts to fit different use cases quickly.
- Limitations:
- Performance: The model’s performance is controlled by its pre-existing knowledge. If the model is not trained on a certain task or domain, it may not perform well.
- Prompt engineering required: Creating effective prompts can require experimentation and can be tricky for complex tasks.
2. What is Fine-Tuning? (refer figure 1):
- Definition: Fine-tuning includes retraining the LLM on a smaller, task-specific dataset, updating its parameters/weights to adapt the model to a specific task or domain.
- How it works: During fine-tuning, a pre-trained LLM (which has general knowledge) is further trained using domain-specific or task-specific data. The model’s internal parameters are updated based on the new data. For example, if you want the model to specialize in legal text generation, you fine-tune it with a dataset consisting of legal documents. After fine-tuning, the model is better at handling legal language.
- Advantages:
- Specialization: Fine-tuning allows the model to specialize in a particular domain or task (e.g., legal documents, scientific literature, medical data).
- Improved performance: Fine-tuned models usually perform better on specific tasks compared to models that depends completely on prompting.
- Limitations:
- Requires additional resources: Fine-tuning requires access to task-specific data, computing power, and AI expertise.
- Overfitting risk: If the fine-tuning dataset is too small or too specific, the model can overfit and lose its generalizability.
- Time-consuming: Fine-tuning takes significantly more time compared to simply providing prompts.
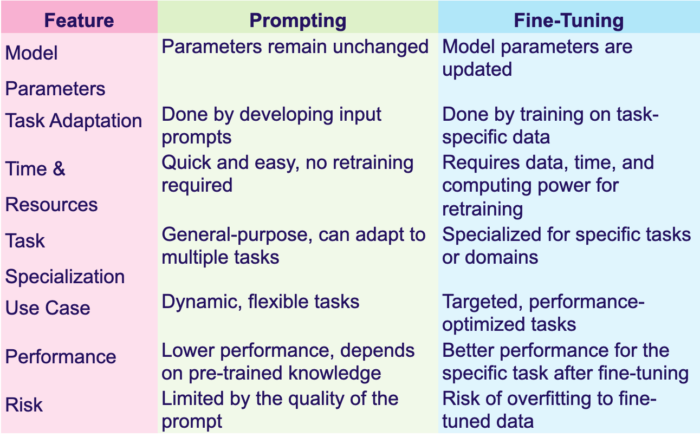
Key Difference: Prompting Vs Fine-Tuning
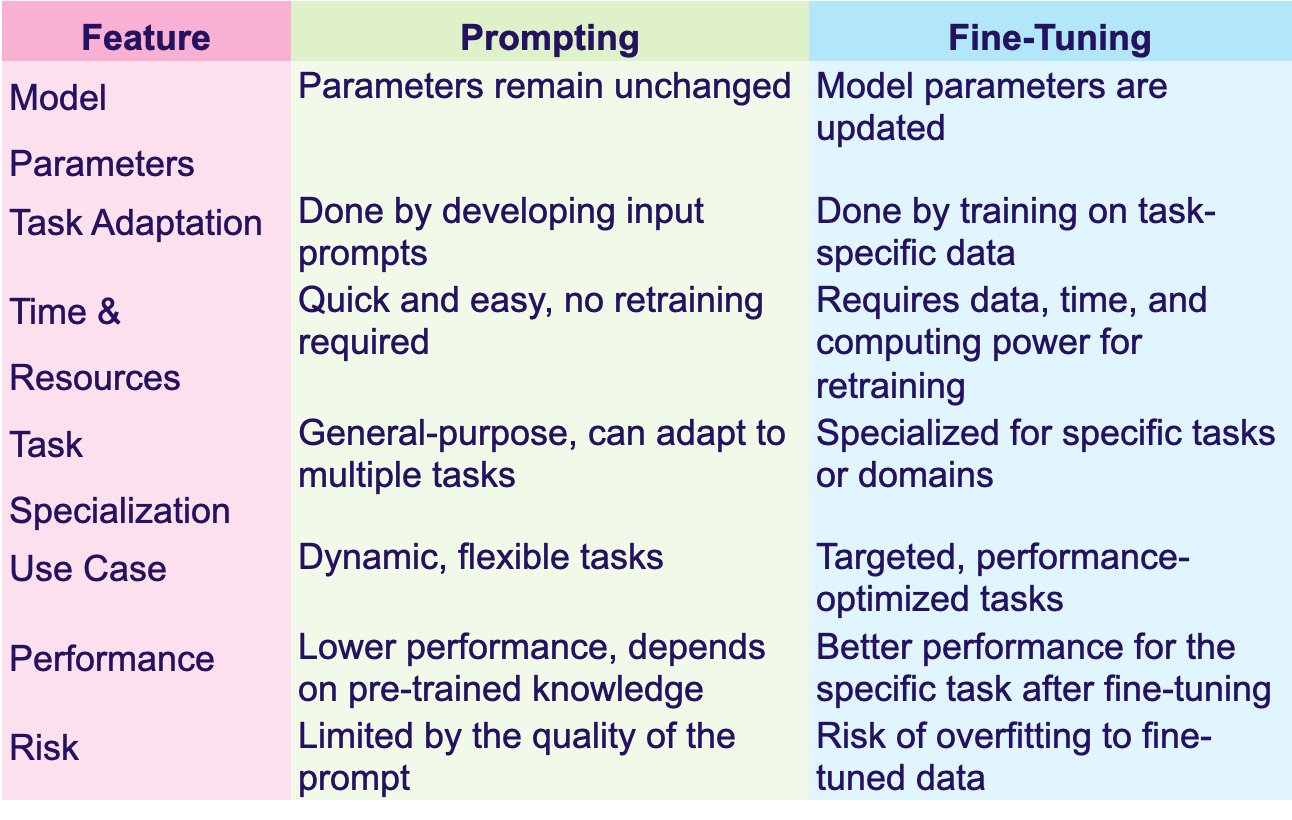
In the figure 2, we can see a detailed features wise comparison. For example, for model training, in prompting technique, no need of parameter tuning, whereas in fine-tuning, the model parameters are updated. Likewise all possible comparisons are shown in the figure.
How a Traditional Fine-Tuning Works?

Here, we see the training process of the model, where it is given various tasks and continuously updates its internal weights or parameters through gradient updates. This repetitive training allows the model to learn from examples and become expert in completing future tasks.
Here I would like to provide a visual representation of how the training happens in traditional fine-tuning of LLMs, in steps.
- Example task #1: The model is given an input-output example (e.g., “sea otter” => “loutre de mer”). This is as the model’s first example task.
- Gradient Update: After completing example task #1, the model performs a gradient update. This is a step in the learning process, where the model adjusts its parameters (weights) based on the errors it made while learning the task, therefore the model is able to improve its performance.
- Example Task #2: The model is then provided with another task (e.g., “peppermint” => “menthe poivrée”). This helps the model learn further.
- Gradient Update: After each task, the model receives another gradient update to adjust its parameters and continue learning from its mistakes.
- Repeated Process: The process repeats across N number of examples such as “plush giraffe” => “girafe peluche”. Each example improves the model through further gradient updates.
- Final Prompt: After being trained on many tasks, the model can generalize and respond to new inputs with partial information, as represented by “cheese =>” with the output left incomplete. The model is now capable of generating a response based on what its learned.
How a prompt works?
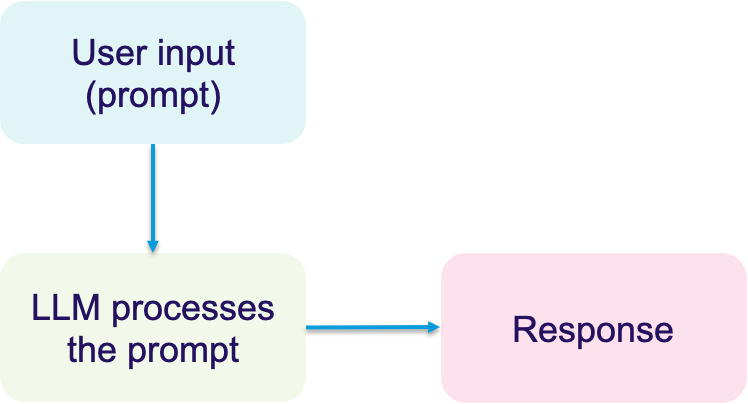
Let us look at how a prompt works within a LLM briefly.
When a user inputs a prompt, the large language model processes this input by analyzing the text and context provided. Then, the model generates a response based on its training and the specific instructions embedded within the prompt. This step-by-step processing highlightes the importance of clear, well-designed prompts in achieving meaningful LLM interactions.
Now we will see very first method of prompt which is zero-prompt along with its implementation.
What is Zero-Shot Learning?

Zero-shot learning means the model can generate a response only based on a task description and prompt, with no examples or additional training (gradient updates).
Example: The task given to the model is to “Translate English to French:”. This is a natural language description of the task that the model is asked to perform.
Prompt: Key characteristic of the model is that the model is expected to generate the correct response (translation of “cheese” into French) without any prior examples of the task.
The model relies completed on its pre-trained knowledge to understand and perform the task.
In zero-shot learning, no gradient updates or additional training are performed. The model does not adjust its internal parameters during the task—it simply uses its existing knowledge base.
What is One-Shot Learning?

One-shot learning is a method where the model is given a task and also provided with one example of how to complete the task before generating a response.
The task given to the model is to “Translate English to French:”. This is the natural language description of the task that informs the model what it is expected to do. The line “sea otter => loutre de mer” provides a single example to demonstrate how the task should be performed. This one-shot example shows the model how to translate the word “sea otter” into French (“loutre de mer”). This example helps guide the model for the next prompt. The prompt provided is “cheese =>”, indicating that the model needs to now translate the word “cheese” into French. The model uses the task description and the provided example to generate the translation for “cheese.”
Key characteristic: The model is given one example (sea otter => loutre de mer) before performing the task. The model uses its understanding of the task and the example to generate the correct translation for “cheese.”
Similar to zero-shot learning, no gradient updates are performed in one-shot learning. The model does not adjust its internal parameters during the task; it only uses the provided task description and example.
What is Few-Shot Learning?

Few-shot learning, where the model is provided with several examples of how to complete the task before generating a response.
The task given to the model is to “Translate English to French:”. This is the natural language description that tells the model what it needs to do.
Examples
- The model is provided with a few examples to learn from:
- “sea otter => loutre de mer” (example 1)
- “peppermint => menthe poivrée” (example 2)
- “plush giraffe => girafe peluche” (example 3)
- These examples help the model understand the task by showing how similar inputs are translated from English to French.
Prompt: The prompt provided is “cheese =>”, indicating that the model needs to translate the word “cheese” into French. After learning from the few examples, the model uses the task description and examples to generate the correct output for “cheese.”
Key characteristic: The model is provided with multiple examples before performing the task. These examples help the model better understand how to complete the task. The model generalizes from the examples and uses that knowledge to generate the correct translation for “cheese.”
Similar to zero-shot and one-shot learning, no gradient updates or additional training are performed during few-shot learning. The model’s internal parameters are not adjusted; it uses the task description and the few examples to complete the task.
Larger models make much better use of in-context learning!
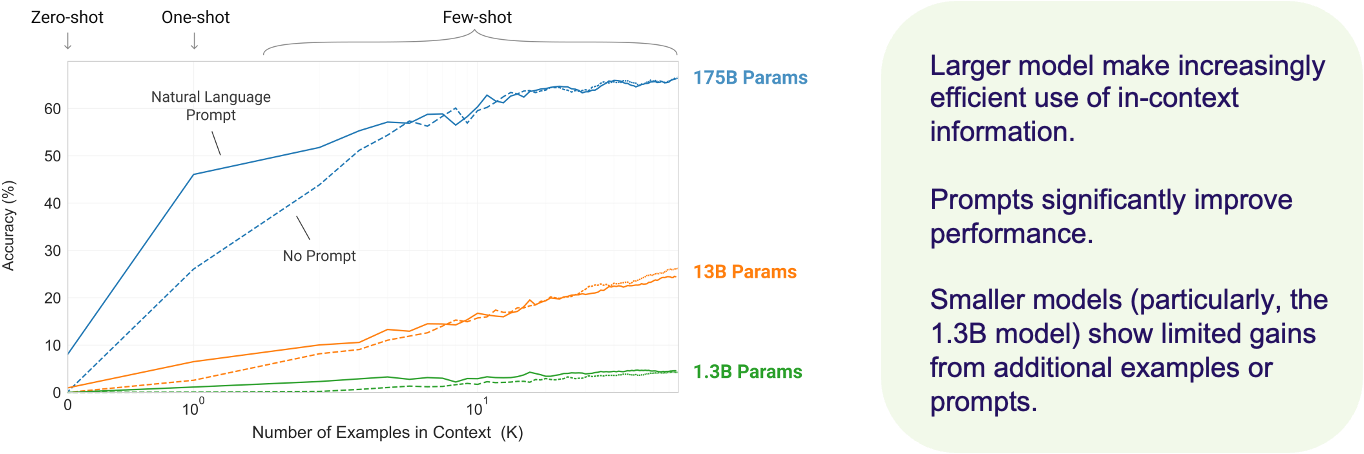
This graph (see figure 8) shows the relationship between model size and how efficiently models learn from in-context information. Specifically, it compares three models with different sizes—1.3 billion, 13 billion, and 175 billion parameters on a task where they are asked to remove random symbols from a word.
- The three models—shown in green, orange, and blue—represent different levels of capacity:
- There are two different scenarios represented:
- With a natural language prompt, shown by the solid lines.
- And without a prompt, represented by the dashed lines.
- On the x-axis, we see the number of examples the model is provided with, ranging from zero-shot learning on the far left to few-shot learning on the right. The y-axis shows the accuracy of the models, that is, how well they perform the task.
- Look at the 175 billion parameter model, represented by the blue line. With just a few examples and a prompt, this model’s accuracy rises sharply and continues to improve as more examples are given.
- Now, compare this to the smaller models—the 13 billion (orange) and 1.3 billion (green). These models also improve with more examples, but their learning curves are much shallower. This means they struggle to benefit from additional examples as efficiently as the larger model does.
- Additionally, when the models aren’t given a prompt, shown by the dashed lines, their performance is significantly worse, especially for the larger model. The natural language prompt plays a critical role in guiding the model’s understanding of the task.
- In summary, this graph shows that larger models make much better use of in-context learning and can generalize better across tasks when provided with a natural language prompt. Smaller models, in contrast, show limited gains from both additional examples and prompts.
- So, in-context learning and prompts are key tools that allow large models to perform tasks efficiently, even with minimal examples.
Performance: Zero-, One-, Few-Shot Methods
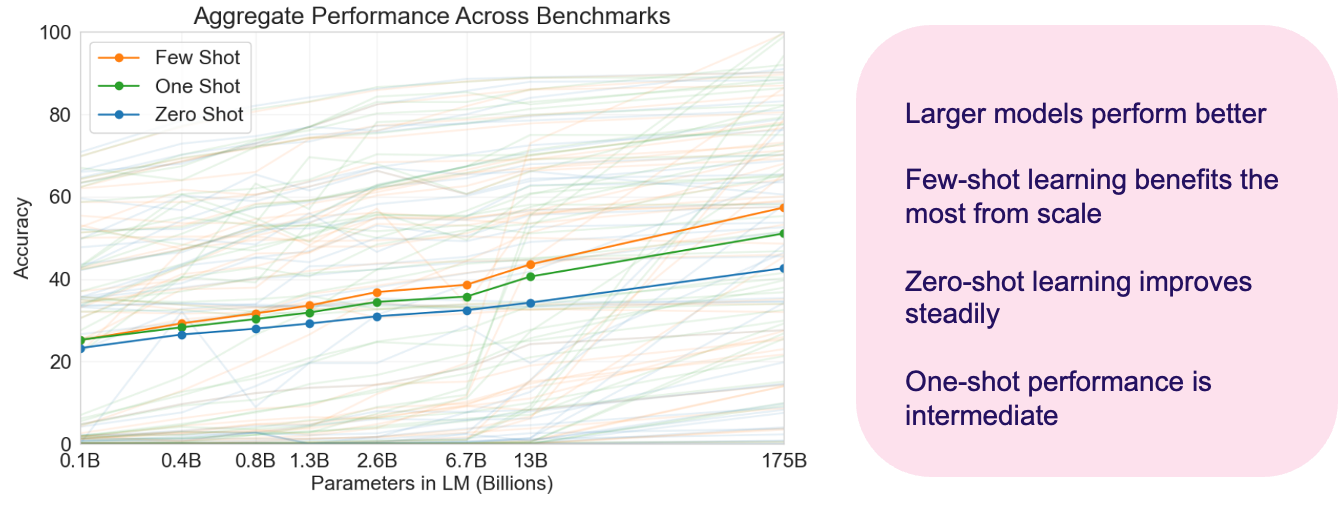
The graph (see figure 9) compares the performance of models with different parameter sizes (ranging from 0.1B to 175B parameters) in three different learning scenarios: few-shot, one-shot, and zero-shot.
Few-shot performance (orange line) shows the steepest upward trajectory, meaning that the largest models (like 175B parameters) perform better in few-shot learning scenarios than in other learning setups. These models improve more rapidly as their size increases.
One-shot performance (green line) shows a more moderate improvement, sitting between the few-shot and zero-shot lines in terms of accuracy.
Zero-shot performance (blue line) shows a steady but less pronounced improvement as model size increases. Larger models still perform well in zero-shot scenarios, but the improvement is less significant than in few-shot learning.
That is for this post! Hope you enjoy reading it!
To more posts on generative AI, visit this: https://ai-researchstudies.com/category/generative-ai/
If you have any doubts regarding prompting and fine-tuning techniques, please leave them in the comment section.
Thanks! see you in the next post 🙂